

YQL (Yahoo! Query Language) is not new, however the concept of a Web Service that accesses Internet data with SQL-like commands, is really cool so should be mentioned on this blog!
The Yahoo! Query Language is an expressive SQL-like language that lets you query, filter, and join data across Web services. YQL hides the complexity of Web service APIs by presenting data as simple tables, rows, and columns.
In this post I work out some examples using YQL to find data of different sources. A good intro article is: Building web applications with YQL and PHP, Part 1, another very useful resource is Using YQL Sensibly - YUIConf 2010 (Christian Heilmann)
The YQL console lets you quickly test commands. Note if you click the blue button (table name) at the right you can get help building your queries, or use DESC to describe the table structure:
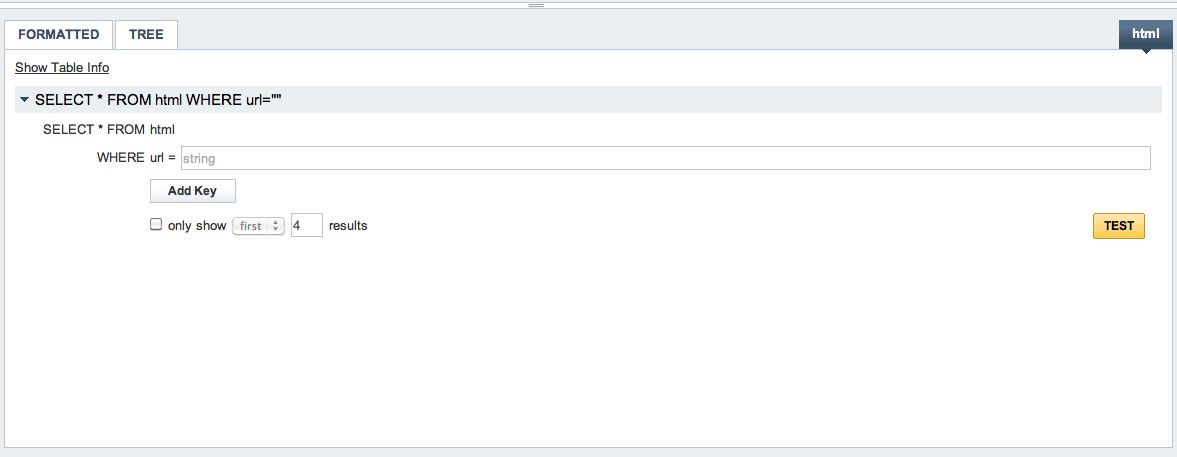
From here on some examples, some easy, others a bit more advanced. Of course a lot more is possible, I still need to experiment more ...
All tweets with my domain in it (or handle)
select * from twitter.search where q='bobbelderbos.com'
Note that I use a standard php script to parse the results. You can get it from here. Alternatively you can use curl
<?php
$yql = "select * from twitter.search where q='bobbelderbos.com'";
// or handle bbelderbos
$query = "http://query.yahooapis.com/v1/public/yql?q=";
$query .= urlencode($yql);
$query .= "&format=json&env=store://datatables.org/alltableswithkeys";
$info = file_get_contents($query, true);
$info = json_decode($info); // echo "<pre>"; print_r($info );
echo "</pre>"; exit;
foreach($info->query->results->results as $item) {
// query->results->results might differ
//process results
}
?>
Get the latest posts from my blog feed
select title, link from rss where url="http://bobbelderbos.com/feed/rss/"
Grabbing html from a page
See an example here how this is done. It shows you how you can get the XPath from firebug, see the screenshot below (corresponding to the 3rd example below):
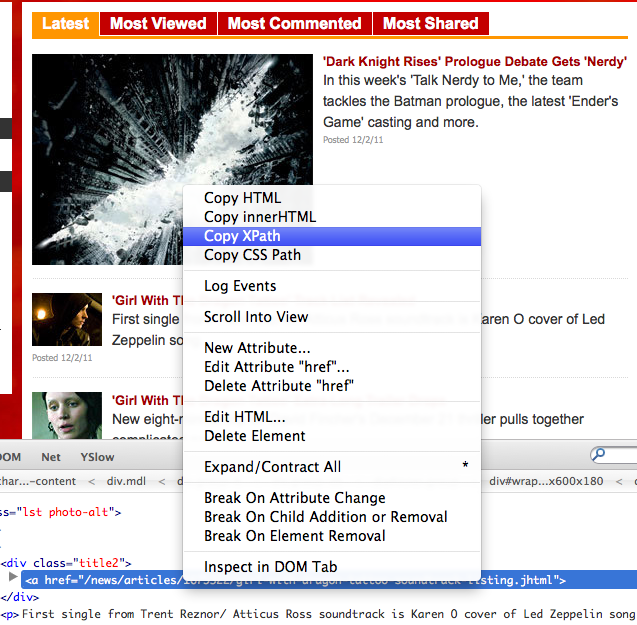
Examples of web scraping:
- select headlines of elpais dot com: select content from html where url="http://elpais.com" and xpath="//h2/a"
- same for NRC (Dutch newspaper): SELECT * FROM html WHERE url="http://www.nrc.nl/" and xpath="//h1/a"
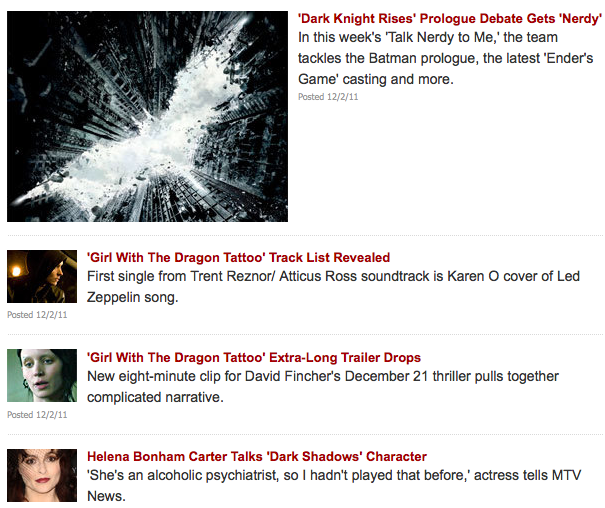
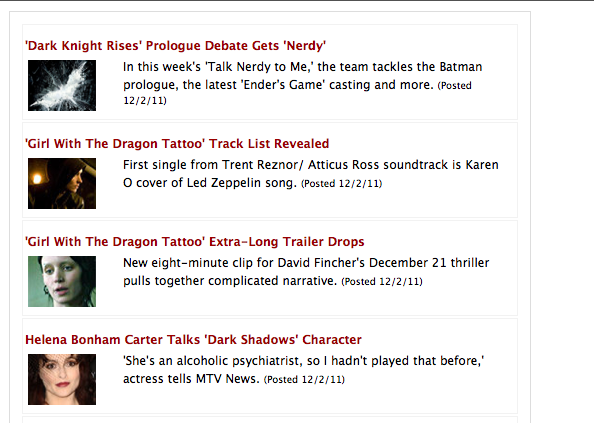
- mashup of MTV movie news (could be interesting to add to sharemovi.es in the future?): SELECT * FROM html WHERE url="http://www.mtv.com/news/latest/movies.jhtml" and xpath="//ol/li" (SELECT * FROM html WHERE url="http://www.imdb.com/news/" and xpath="//h1" -- from IMDb I got a permission denied)
Original MTV movie site:
After getting data with YQL, and styling a bit:
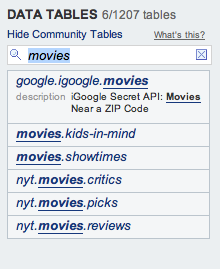
Open data tables
With the addition of Open Data Tables, developers from anywhere can contribute YQL Tables to describe any data source on the Web, making YQL easily extensible. Today, there are more than thousand community contributed tables! You can easily build your own data tables - the source code of already committed tables is on github
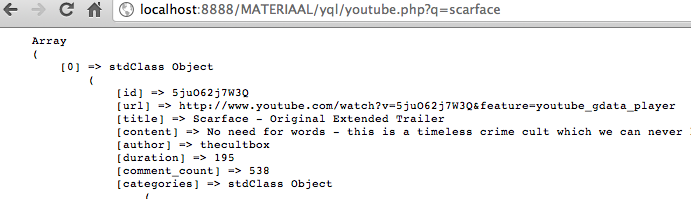
Get youtube videos for instant trailers
select * from youtube.search where query='scarface trailer' limit 5
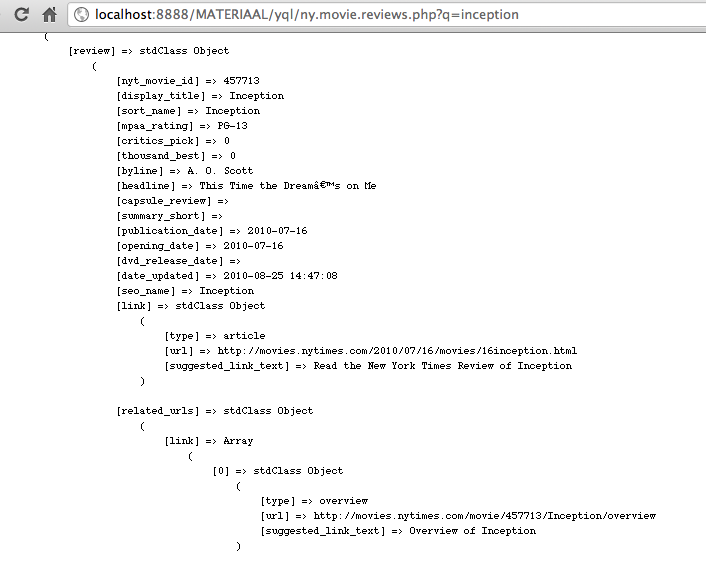
Get movie reviews from NY times movie API
SELECT * FROM nyt.movies.reviews WHERE apikey="---" and query="inception" (again, could be interesting to add to to sharemovi.es ...)
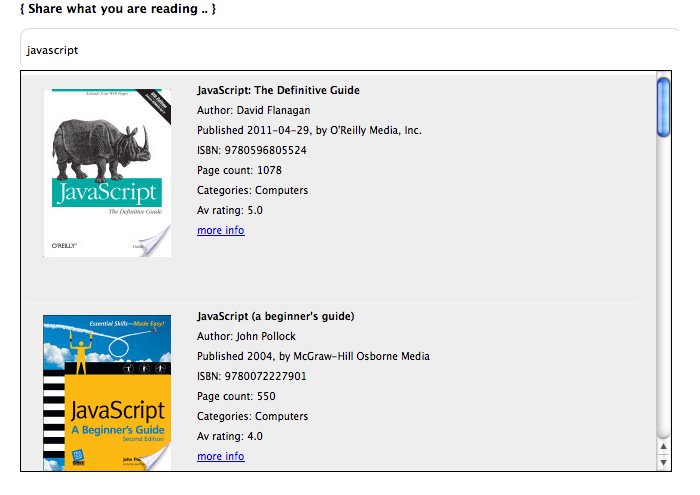
Get book info from google books API
This example poors the YQL parsed results in a juery/php autocomplete
SELECT * FROM google.books WHERE q='javascript' AND maxResults=10 AND startIndex=2
Links and resources
Again, you can go much further, YQL is very powerful: embedded queries, create/import your own tables, a lot more APIs (some require keys like Amazon, Facebook, Twitter and Lastfm). Below some extra resources:
- YQL Manual
- YQL console
- YQL screencasts
- Using YQL Sensibly - YUIConf 2010 (by Christian Heilmann)
- IMB developerWorks - intro YQL
- Nettuts guide to YQL
- Help building queries
- Python YQL
Are you using YQL?
I hope you enjoyed this post. Feel free to comment below what your experience is with YQL and/or what you would get out of this service ...
