

To save time and concentrate as a developer, Vim is the best place to be. But I cannot code everything from memory so I made a tool to lookup stackoverflow questions and answers without leaving Vim.
Searching Google for programming related questions I found out that about 80% of the times I end up at Stack Overflow which has tons of useful information!
What if I could search this huge Q&A database from the command line? I built a Python class to do so. But to be able to run it inside a Vim buffer you will need the Vim plugin conque and some settings in .vimrc. With that setup you can search Stack Overflow interactively in a Vim split window and copy and paste useful code snippets back and forth.
In the following sections I will show you how it works...
Setup / config
- 1. Install
- - make sure you use 2.2, 2.1 gave me some issues. Just download the file, open vim and run :so %, then exit. Opening Vim again and you can use the plugin.
- 2. Get a copy of the
stackoverflow_cli_search script
- 3. Setup a key mapping in .vimrc to open up the script in vertical split (at least that is how I like it):
nmap ,s :ConqueTermVSplit python ...path-to-script.../stackoverflow_cli_search.py
Note that I use comma (,) as mapleader - in .vimrc add: let mapleader = ","
I made two similar key mappings as well to:
- a. try things in Python while I am coding:
nmap cp :ConqueTermVSplit python
- b. search github code (see this blogpost):
nmap ,g :ConqueTermVSplit python ...path-to-script.../github_search.py
4. When coding you can just type ,s to start searching Stack Overflow - ,g for github (if you downloaded the script from the previously mentioned post as well) - or cp to get a interactive python shell. All in a new Vim vertical split window, so no need to leave the terminal, you can switch between the two windows hitting ctrl+w twice.
Here you see a printscreen of the split window:
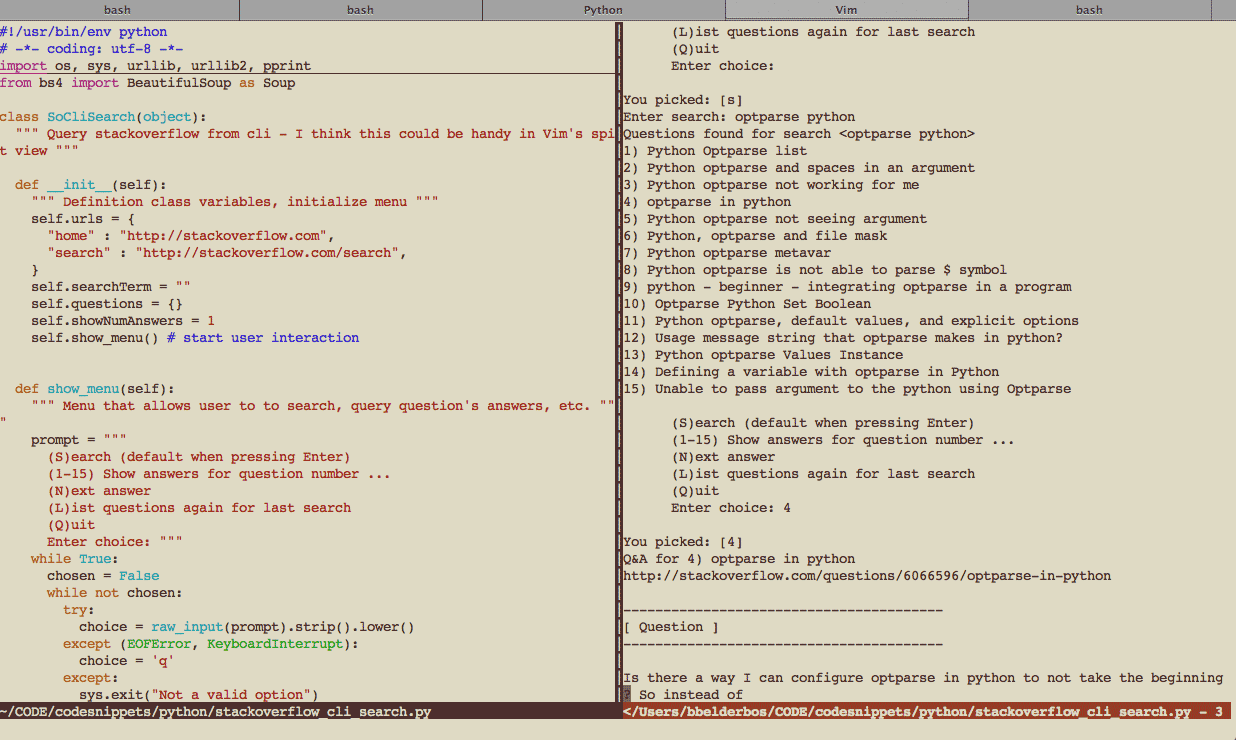
5. When you like to copy a code snippet you'll find, hit Esc and conque goes into normal mode so you can select with V (visually select current line) + a motion command + y (yank). Thenk you move to your code window (2x ctrl+w) and p (paste) the yanked buffer. To resume with the script go back to the stakcoverflow window (again 2x ctrl+w) and go into Insert mode with i, I, a, A, etc.
Example
The example below I literally pasted into this blog post staying in Vim (in the right window typing : ESC-Vgg-y to copy the whole buffer, then 2x ctrtl+w to go back to this post and there run: p to paste:
(S)earch (default when pressing Enter)
(1-15) Show answers for question number ...
(N)ext answer
(L)ist questions again for last search
(Q)uit
Enter choice:
You picked: [s]
Enter search: python re.compile
Questions found for search <python re.compile>
1) python regex re.compile match
2) python re.compile match percent sign %
3) Case insensitive Python regular expression without re.compile
4) Python and re.compile return inconsistent results
5) Does re.compile() or any given Python library call throw an exception?
6) python re.compile Beautiful soup
7) python re.compile strings with vars and numbers
8) how to do re.compile() with a list in python
9) python regex re.compile() match string
10) Python re.compile between two html tags
11) Python BeautifulSoup find using re.compile for end of string
12) Python: How does regex re.compile(r'^[-w]+$') search? Or, how does regex
work in this context?
13) Clean Python Regular Expressions
14) Matching a specific sequence with regex?
15) Regex negated capture group returns answer
(S)earch (default when pressing Enter)
(1-15) Show answers for question number ...
(N)ext answer
(L)ist questions again for last search
(Q)uit
Enter choice: 9
You picked: [9]
Q&A for 9) python regex re.compile() match string
http://stackoverflow.com/questions/8012320/python-regex-re-compile-match-string
----------------------------------------
[ Question ]
----------------------------------------
Gents,
I am trying to grab the version number from a string via python regex...
Given filename: facter-1.6.2.tar.gz
When, inside the loop:
import re
version = re.split('(.*d.d.d)',sfile)
print version
How do i get the 1.6.2 bit into version
Thanks!
----------------------------------------
[ Answer #1 ]
----------------------------------------
Two logical problems:
1) Since you want only the 1.6.2 portion, you don't want to capture the .* part before the first d, so it goes outside the parentheses.
[truncated]
(S)earch (default when pressing Enter)
(1-15) Show answers for question number ...
(N)ext answer
(L)ist questions again for last search
(Q)uit
Enter choice: n
You picked: [n]
----------------------------------------
[ Answer #2 ]
----------------------------------------
match = re.search(r'd.d.d', sfile)
if match:
version = match.group()
(S)earch (default when pressing Enter)
(1-15) Show answers for question number ...
(N)ext answer
(L)ist questions again for last search
(Q)uit
Enter choice: n
You picked: [n]
----------------------------------------
[ Answer #3 ]
----------------------------------------
>>> re.search(r"d+(.d+)+", sfile).group(0)
'1.6.2'
(S)earch (default when pressing Enter)
(1-15) Show answers for question number ...
(N)ext answer
(L)ist questions again for last search
(Q)uit
Enter choice: n
You picked: [n]
All answers shown, choose a question of previous search (L) or press Enter (o
r S) for a new search
(S)earch (default when pressing Enter)
(1-15) Show answers for question number ...
(N)ext answer
(L)ist questions again for last search
(Q)uit
Enter choice:
The script
See below (download at Github):
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os, sys, urllib, urllib2, pprint
from bs4 import BeautifulSoup as Soup
class StackoverflowCliSearch(object):
""" Query stackoverflow from cli
I think this could be handy in Vim's spit view (with ConqueTerm) """
def __init__(self):
""" Definition class variables, initialize menu """
self.searchTerm = ""
self.questions = {}
self.showNumAnswers = 1 # show 1 answer first, then 1 by 1 pressing N
self.show_menu() # start user interaction
def show_menu(self):
""" Menu that allows user to to search, query question's answers, etc. """
prompt = """
(S)earch (default when pressing Enter)
(1-15) Show answers for question number ...
(N)ext answer
(L)ist questions again for last search
(Q)uit
Enter choice: """
while True:
chosen = False
while not chosen:
try:
choice = raw_input(prompt).strip().lower()
except (EOFError, KeyboardInterrupt):
choice = 'q'
except:
sys.exit("Not a valid option")
if choice == '': choice = 's' # hitting Enter = new search
print 'nYou picked: [%s]' % choice
if not choice.isdigit() and choice not in 'snlq':
print "This is an invalid option, try again"
else:
chosen = True
if choice.isdigit() : self.show_question_answer(int(choice))
if choice == 's': self.search_questions()
if choice == 'n': self.show_more_answers()
if choice == 'l': self.list_questions(True)
if choice == 'q': sys.exit("Goodbye!")
def search_questions(self):
""" Searches stackoverflow for questions containing the search term """
self.questions = {}
self.searchTerm = raw_input("Enter search: ").strip().lower()
data = {'q': self.searchTerm }
data = urllib.urlencode(data)
soup = self.get_url("http://stackoverflow.com/search", data)
for i,res in enumerate(soup.find_all(attrs={'class': 'result-link'})):
q = res.find('a')
self.questions[i+1] = {}
self.questions[i+1]['url'] = "http://stackoverflow.com" + q.get('href')
self.questions[i+1]['title'] = q.get('title')
self.list_questions()
def get_url(self, url, data=False):
""" Imports url data into Soup for easy html parsing """
u = urllib2.urlopen(url, data) if data else urllib2.urlopen(url)
return Soup(u)
def list_questions(self, repeat=False):
""" Lists the questions that were found with the last search action """
if not self.questions:
print "No questions found for search <%s>" % self.searchTerm
return False
if not self.questions and repeat:
print "There are no questions in memory yet, please perform a (S)earch first"
return False
print "Questions found for search <%s>" % self.searchTerm
for q in self.questions:
print "%d) %s" % (q, self.questions[q]["title"])
def show_question_answer(self, num):
""" Shows the question and the first self.showNumAnswers answers """
entries = []
if num not in self.questions:
print "num <%s> does not appear in questions dict" % str(num)
return False
print "Q&A for %d) %s n%sn" %
(num, self.questions[num]['title'], self.questions[num]['url'])
soup = self.get_url(self.questions[num]['url'])
for i,answer in enumerate(soup.find_all(attrs={'class': 'post-text'})):
qa = "Question" if i == 0 else "Answer #%d" % i
out = "%sn[ %s ]n%sn" % ("-"*40, qa, "-"*40)
out += ''.join(answer.findAll(text=True))
# print the Q and first Answer, save subsequent answers for iteration with option (N)ext answer
if i <= self.showNumAnswers:
print out
else:
entries.append(out)
self.output = iter(entries)
def show_more_answers(self):
""" Result of option (N)ext answer: iterates over the next answer (1 per method call) """
if not self.output:
print "There is no QA output yet, please select a Question listed or perform a (S)earch first"
return False
try:
print self.output.next()
except StopIteration as e:
print "All answers shown, choose a question of previous search (L) or press Enter (or S) for a new search"
# instant
so = StackoverflowCliSearch()
