October
2nd,
2011

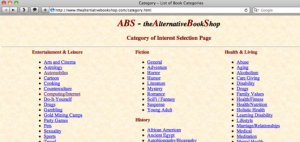
I wanted to have a book category list for a potential feature in My Reading List. I found this page. Then I wondered how I could parse the html to reuse the categories. It turned out to be pretty easy in Perl :)
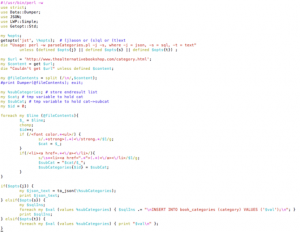
You can download the script here. It does the following:
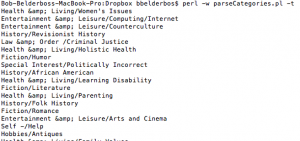
- 1. Usage: perl -w parseCategories.pl -j -s, where -j = json, -s = sql, -t = text
Sql would be to import the data into a table for re-use (e.g. autocomplete) - 2. it uses LWP::Simple to import the content of the mentioned website into a variable
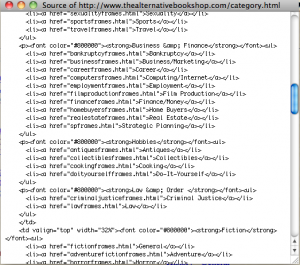
- 3. it splits the content in an array and loops over the lines, checking for the patterns:
a. category (font.*<ul>),
b. subcategory (<li><a href...)
- it puts those in a hash - 4. depending the cli option, it provides the output
Perl's motto is TMTOWTDI (There's more than one way to do it), so I would be happy to hear any suggestions to improve this script.
At least it got the job done. It was just a quick test. Ideally you would want to make it re-usable:
1. receive URL from cli as well
2. put parsing in functions and let user define those as well.
- with this in place it could be extended to be a generic/simple URL/content parser.