

In spite of my proposed Scala, HTML5, and Mobile learning, I will start this New Year learning Ruby :) - I am about to read Eloquent Ruby, but before that I wanted to wet my apetite with a practical case ...
The challenge
Browsing http://facebook.stackoverflow.com/, I saw a nice one to work on: Getting all likes on my domain (facebook). So how to get stats on likes for each of your blog posts? Read on ...
How to do it

New here? You might want to subscribe to my blog by email or RSS.
It is nice to get a feel of a language by first playing with it, I took the same approach learning Perl. Of course I had to use Google a lot for even basic things (Ruby hashes, loops, the very useful Perl Dumper variant "pp", etc.), but I soon became convinced that Ruby is fun to learn and a powerful language to have in your toolkit.
First step is to make a sitemap XML file of your site. It turned out I had to do that anyways for SEO purposes. For Wordpress there is an excellent plugin. You can see my sitemap here.
So we start scripting. First we need to load that file from the web with a call to "Net::HTTP.get_response" (requires 'net/https')
Next you want to parse the XML to get all the URLs. REXML makes that simple with "REXML::Document.new(xml_data)" and then you use "doc.elements.each('urlset/url/loc')" to loop over the URLs
Then the real data crunching: you reach out to https://graph.facebook.com/?ids= which (I just discovered) does except a comma-seperated list of URLs. Keep in mind the https so require 'net/https' and use "http.use_ssl = true". Obviously this is the desired way to do it: clustering all URLs together to make one big query instead of hundreds of small ones. You do need to shave the last comma off, otherwise the query will fail (url[0..-2])
Facebook Graph returns JSON so this needs to be parsed with JSON.parse (requires 'json'). I put all the results in the "likes" hash (keys are URLs, values are the number of likes). You could sort it numerically descending in Ruby, but I was comfortable doing it from the cli with "ruby getBlogLikeStats.rb | sort -n -k2"
And that is all there is to it. Building this in Ruby turned out to be a painless and fun process. And that for somebody that still has to learn the language basics, nice!
Source
Source is printed below and you can download it here.
#!/usr/bin/env ruby
require 'net/https'
require 'rexml/document'
require 'json';
urlXml = 'http://bobbelderbos.com/sitemap.xml'
url = 'https://graph.facebook.com/?ids='
likes = Hash.new;
xml_data = Net::HTTP.get_response(URI.parse(urlXml)).body
doc = REXML::Document.new(xml_data)
doc.elements.each('urlset/url/loc') { |element| url += element.text + "," }
uri = URI.parse(url[0..-2])
http = Net::HTTP.new(uri.host, uri.port)
http.use_ssl = true
request = Net::HTTP::Get.new(uri.path + "?" + uri.query)
response = http.request(request)
data = response.body
result = JSON.parse(data)
result.each { |url| likes[url[1]['id']] = url[1]['shares'] }
likes.each do|url,numLikes|
puts "#{url}: #{numLikes}"
end
Have fun!
Update 08.01.2012: What about Twitter?
With the Tweetmeme API you can easily query the amount of tweets. Only incovenience is that http://api.tweetmeme.com/url_info.json?url accepts only 1 URL at the time it seems, so you need to make a call for each URL (as opposed to the earlier mentioned Facebook Graph API that does handle multiple URLs in one call)
Ruby code to get your tweet stats:
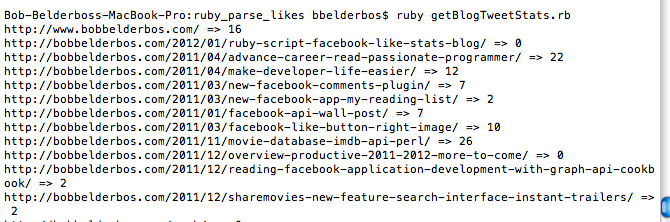
Executing the script from CLI:
#!/usr/bin/env ruby
# copyright (c) 2012 Bob Belderbos
# created: January 2012
require 'net/http'
require 'uri'
require 'rexml/document'
require 'json'
require 'pp'
urlXml = 'http://bobbelderbos.com/sitemap.xml'
url = 'http://api.tweetmeme.com/url_info.json?url='
xml_data = Net::HTTP.get_response(URI.parse(urlXml)).body
doc = REXML::Document.new(xml_data)
doc.elements.each('urlset/url/loc') do |element|
url += element.text
resp = Net::HTTP.get_response(URI.parse(url))
data = resp.body
result = JSON.parse(data)
print "#{result['story']['url']} => #{result['story']['url_count']}n"
end
