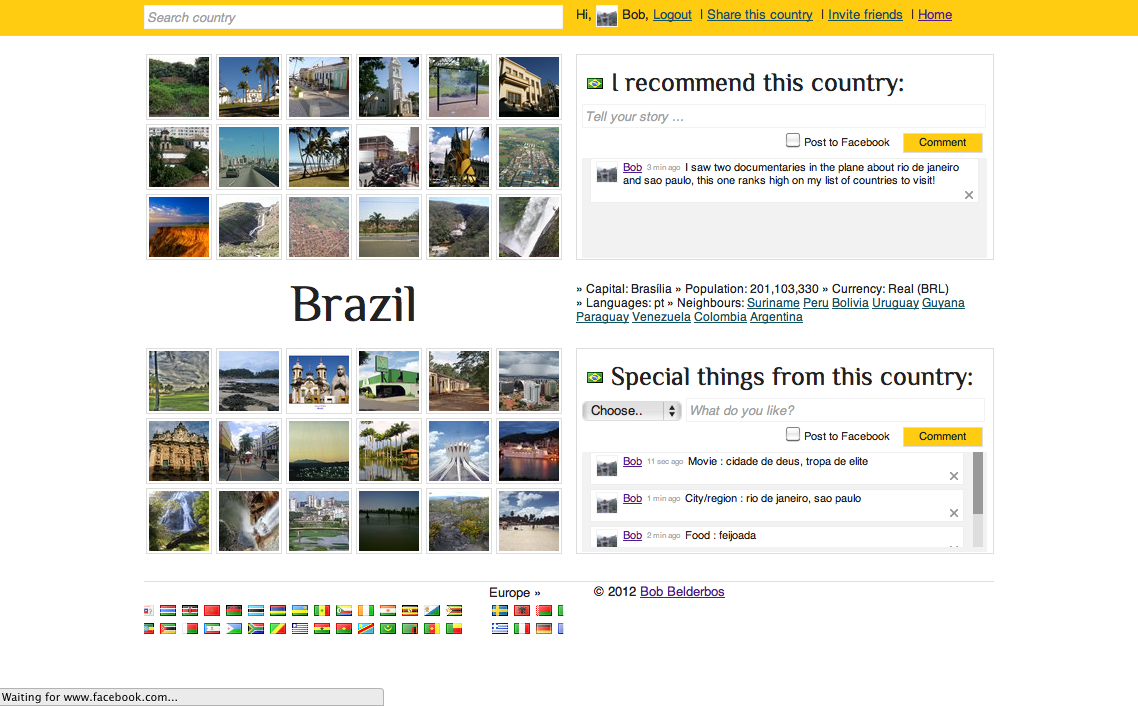
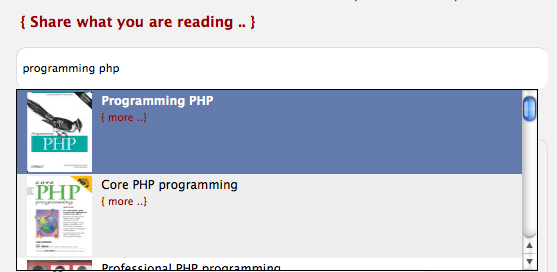
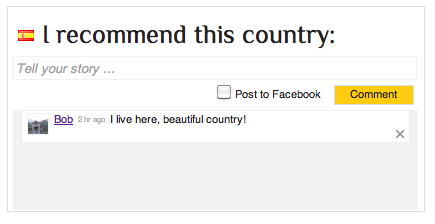
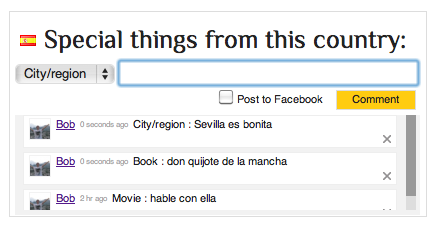
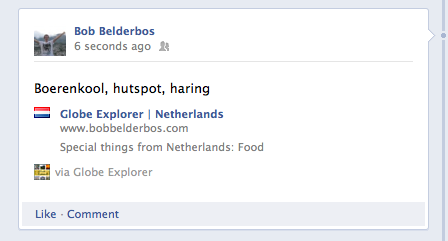
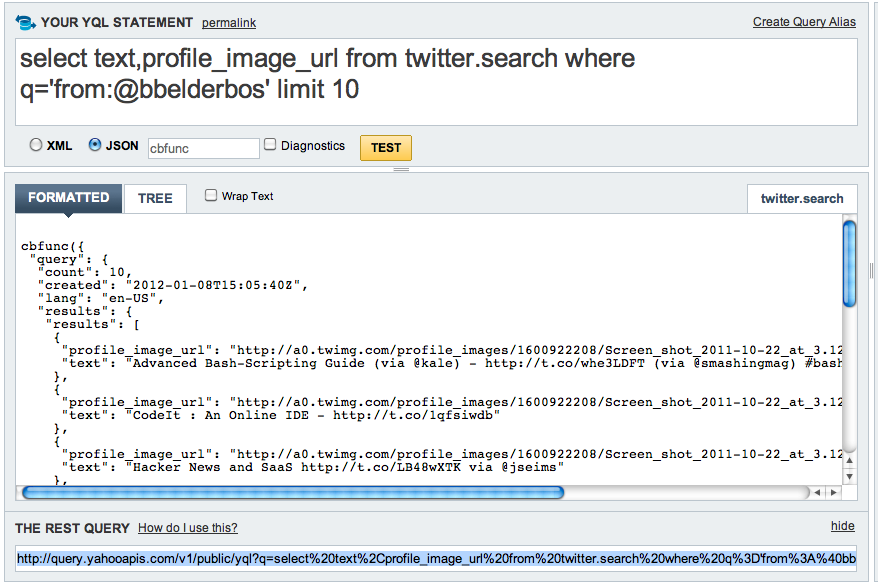
The why and how of Globe Explorer's design change
I was not 100% happy with the first design of Globe Explorer, but now I am. In this post some screenshots and inside info of the new design. I hope you like and enjoy it ...
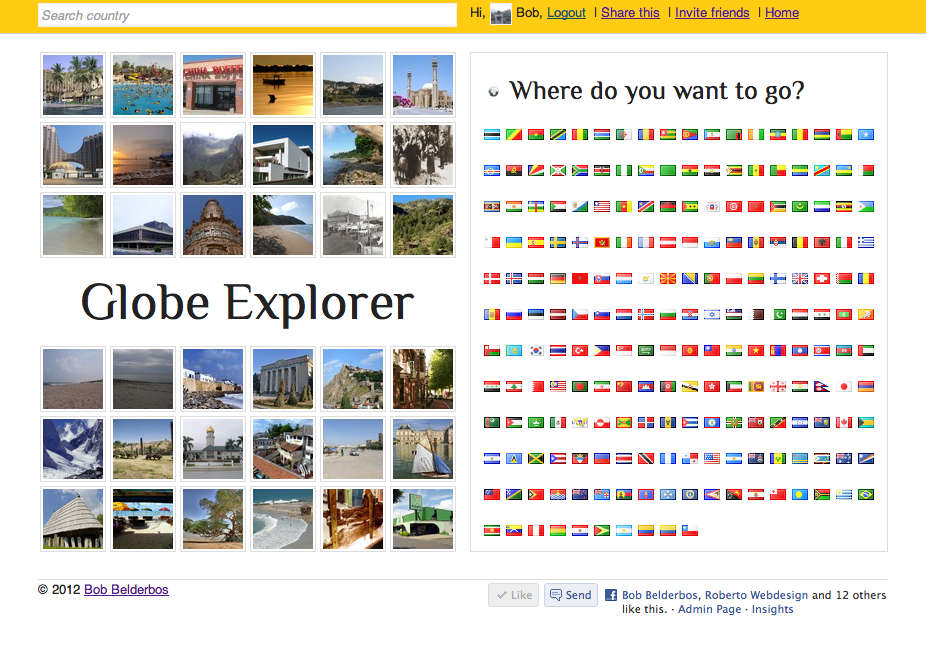
First design
This was the first design I presented two weeks ago:
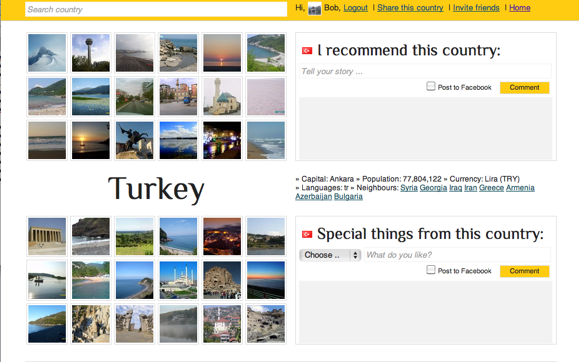
There were some issues with this design. First of all the Tixik API mapped photos to various countries. I addressed this to them, but I am waiting for an answer ... So not all photos were accurate. Secondly I loaded a lot of photos per country which might have slowed down the experience for users with a slower internet connection.
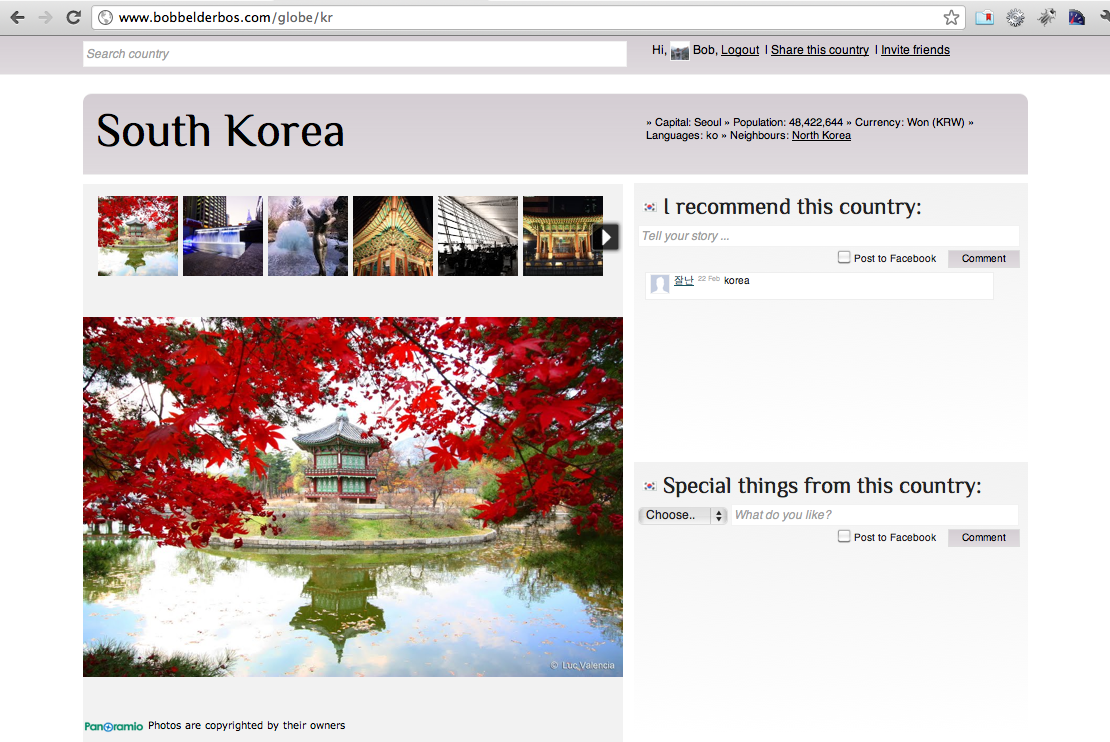
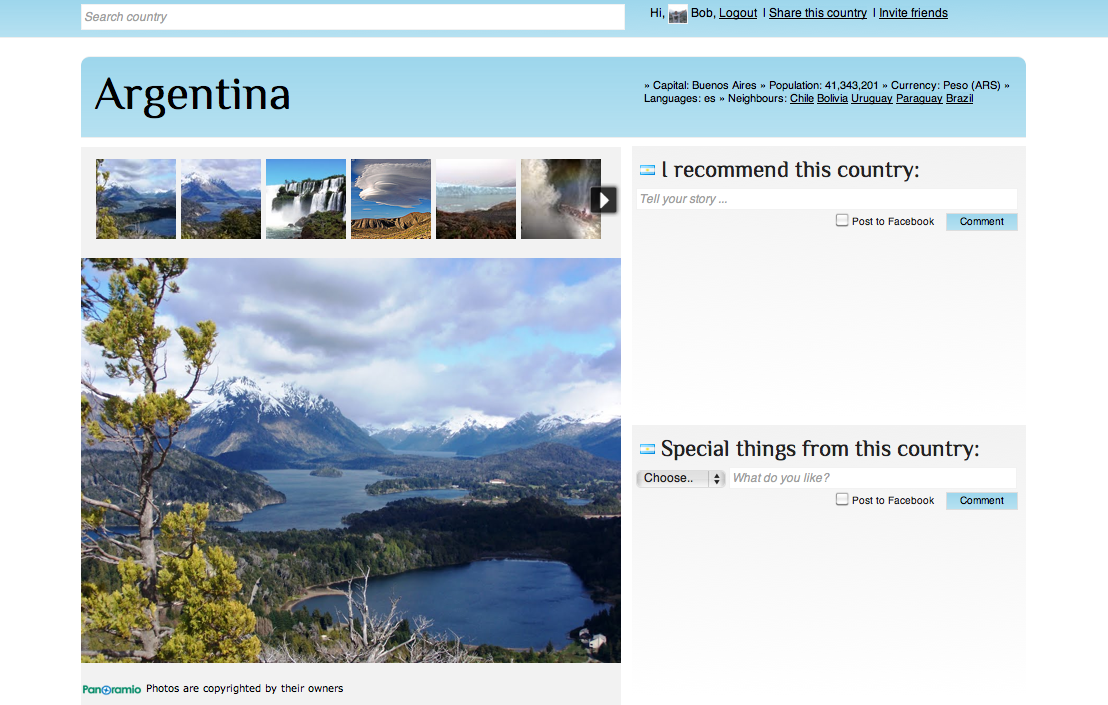
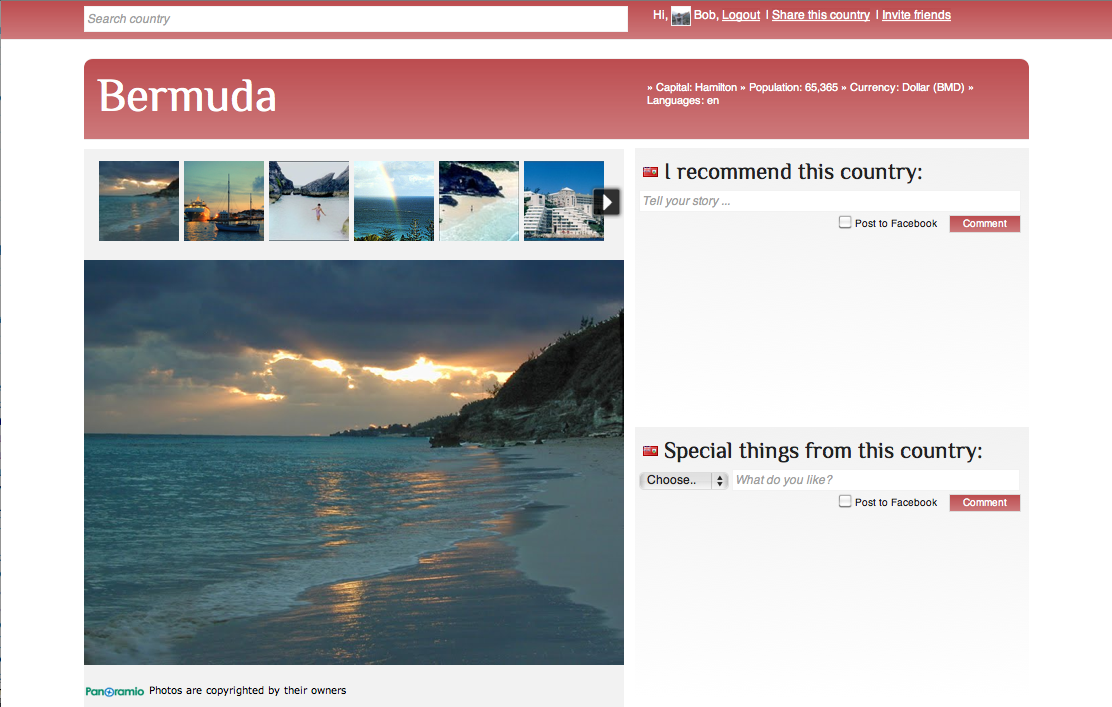
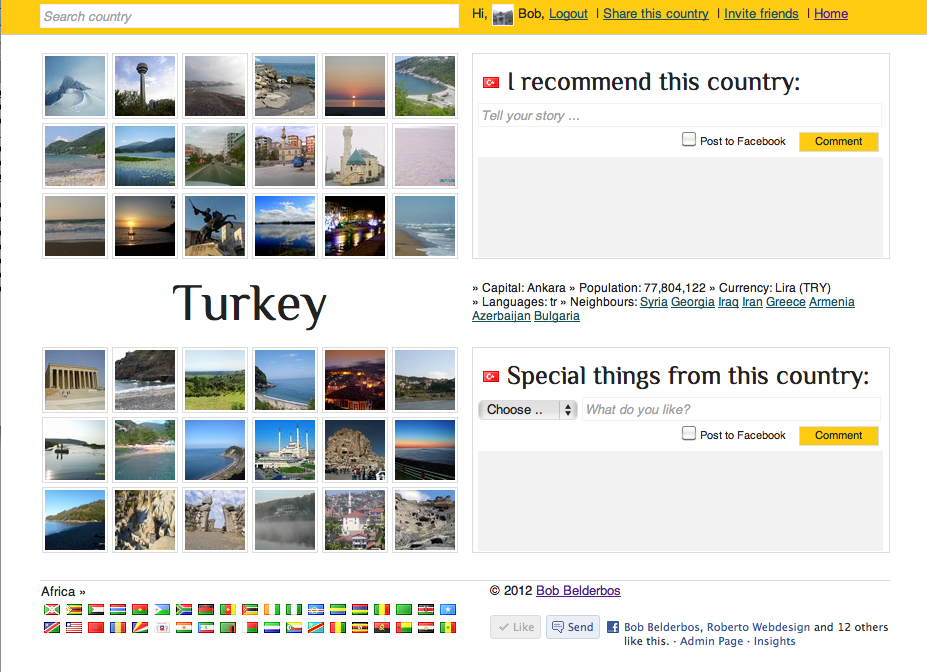
New design
I improved quite some things I think:
- I found a very easy alternative for the image issue. I saw that most photos were linked to Panoramio, so I went out to see if I could talk to this source directly. Honestly, I didn't even use the Javascript API because I was pretty impressed with the widgets they offer. I use the photo_list widget with the countryname as variable:
<iframe id="panoramio" src="http://www.panoramio.com/wapi/template/photo_list.html?tag= <?php echo $countryAttributes[0]['country'];?> &width=600&height=600&list_size=6&position=top&bgcolor=%23f2f2f2" frameborder="0" width="600" height="600" scrolling="no" marginwidth="0" marginheight="0"> </iframe>
$gradientColor = getFlagAverageColor($country);
..
function getFlagAverageColor($country){
// http://stackoverflow.com/questions/1746530/get-image-color
$filename = "img/flags/".strtolower($country).".gif";
$image = imagecreatefromgif($filename);
$width = imagesx($image);
$height = imagesy($image);
$pixel = imagecreatetruecolor(1, 1);
imagecopyresampled($pixel, $image, 0, 0, 0, 0, 1, 1, $width, $height);
$rgb = imagecolorat($pixel, 0, 0);
$color = imagecolorsforindex($pixel, $rgb);
return rgb2html($color['red'], $color['green'], $color['blue']);
}
function rgb2html($r, $g=-1, $b=-1) {
if (is_array($r) && sizeof($r) == 3)
list($r, $g, $b) = $r;
$r = intval($r); $g = intval($g);
$b = intval($b);
$r = dechex($r<0?0:($r>255?255:$r));
$g = dechex($g<0?0:($g>255?255:$g));
$b = dechex($b<0?0:($b>255?255:$b));
$color = (strlen($r) < 2?'0':'').$r;
$color .= (strlen($g) < 2?'0':'').$g;
$color .= (strlen($b) < 2?'0':'').$b;
return '#'.$color;
}
I found a nice PHP class to calculate a lighter tone of that color. It also matches the foreground color to W3C color visibility guidelines. Quite neat! The calculated flag gradient also shows up in the autocomplete:

I took the homepage out. It had all the flags which was nice, but it didn't result in a fast load of the homepage. I do load the flags in the footer carousel, that did not change, but the potential delay does not jump in the eye (and if it does effect user experience I might get it out after all). I thought it was more fun to select some preferred countries, put them in an array and randomly select one and load its page. So now, when you go to the homepage, you get one of those preferred countries and you dive right in. Usually the specs show one or more neighbour countries so you can keep browsing countries. If not, I hope it is obvious you can use the search box at the top to lookup any country (or click on the flags in the footer).
Feedback
Before showing off some examples, please let me know if you have any feedback. I am open to any comments. Thanks for the designers that had a critical look at the first version. Especially the feedback on gradients was very useful. Thanks guys!
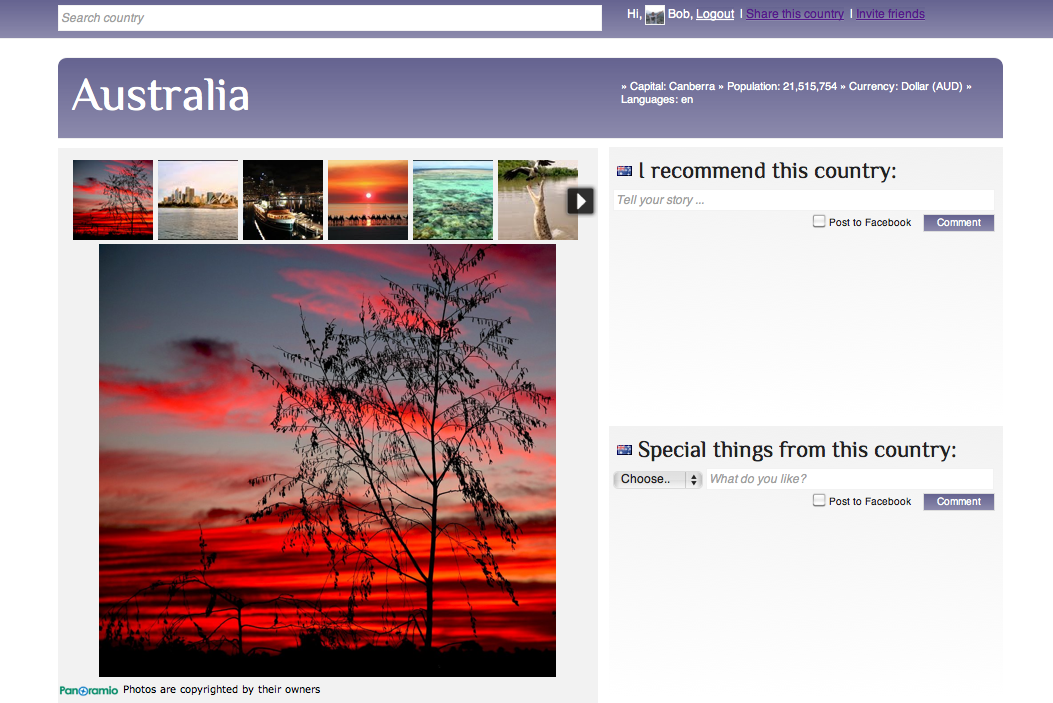
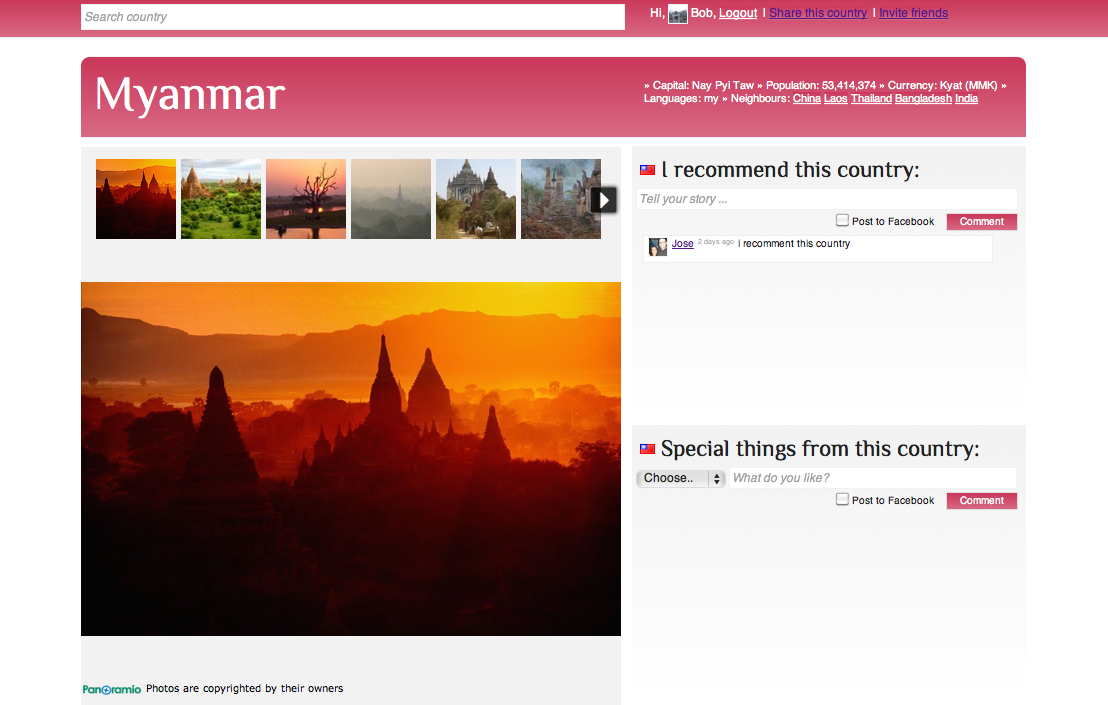
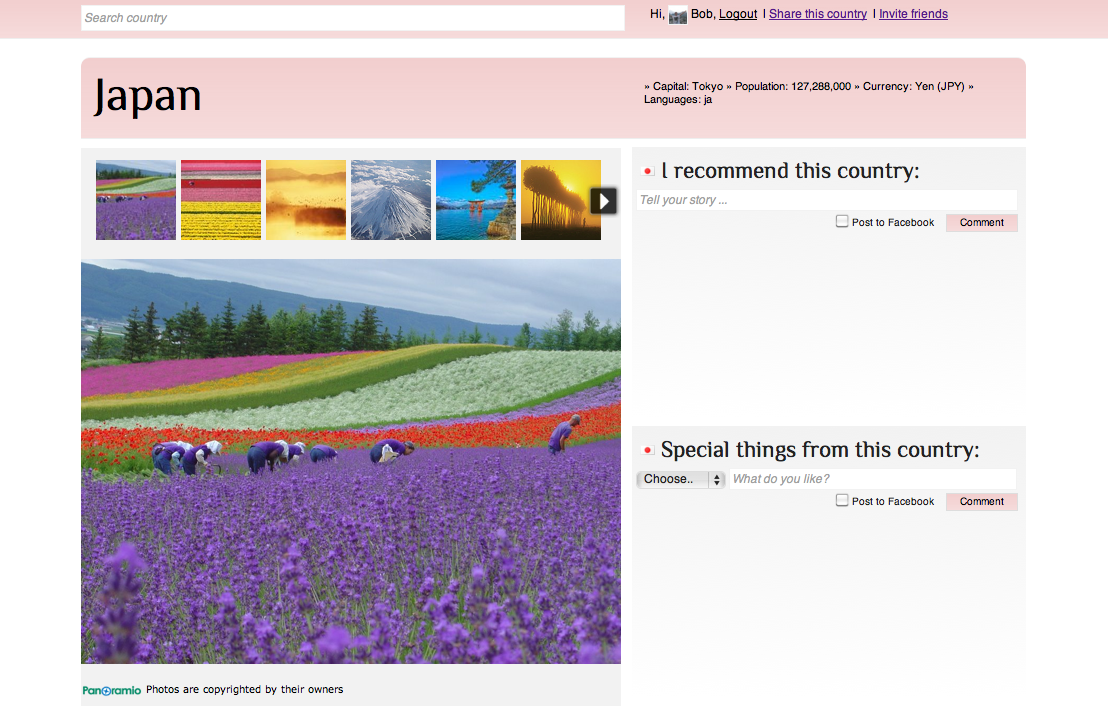
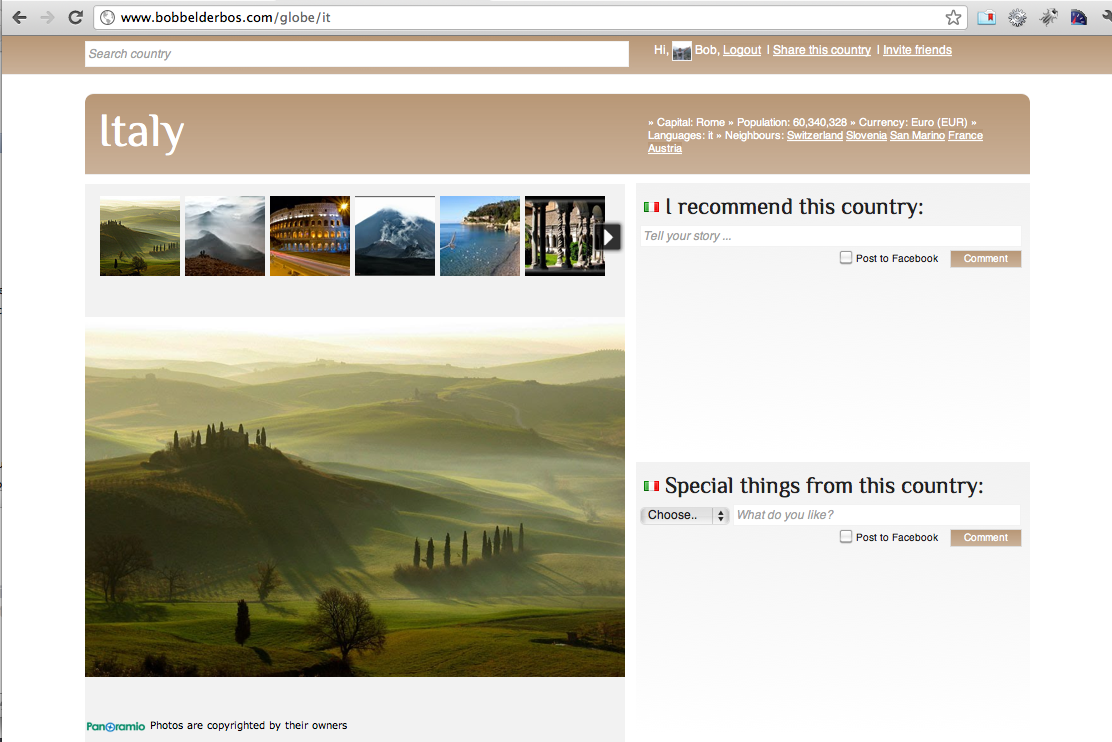
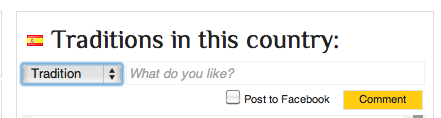
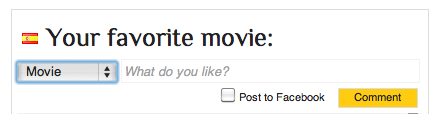
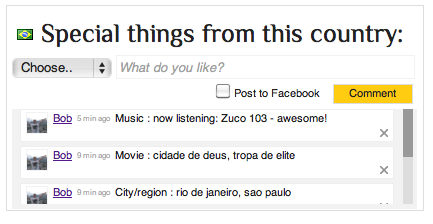
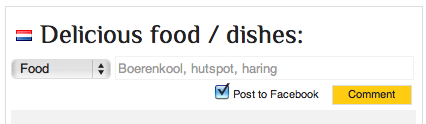
Examples
Check out the site here. I also made some printscreens: