Today two posts about enhancements in Sharemovi.es. In this post I will show you how to make a multifunctional autocomplete box. In the next article I show you how to dynamically load in IMDB vote results for a particular movie.
Autocompletes are around for a long time, but I still love them for my apps. It makes the app flow faster and navigation can be much shorter not cluttering the page.
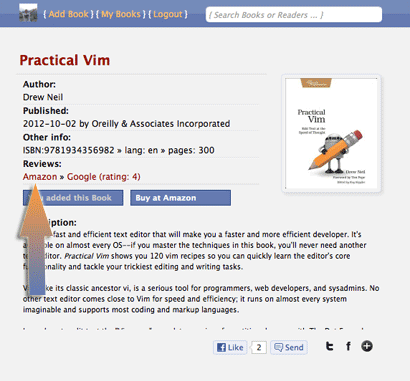
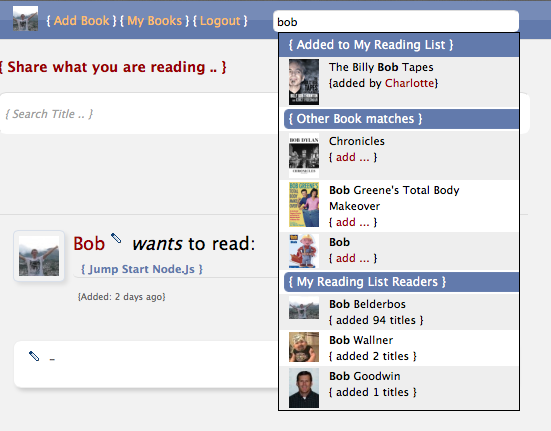
I implemented a multi-use autocomplete some time ago for FB Reading List:
I will show you a similar approach I took for sharemovi.es.
How it works
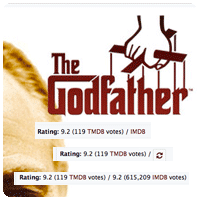
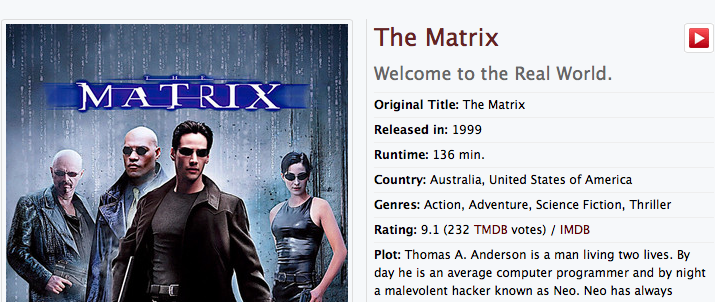
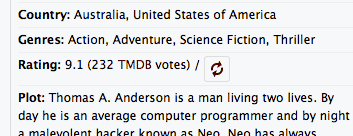
When you search for "be" it finds movies for that string:
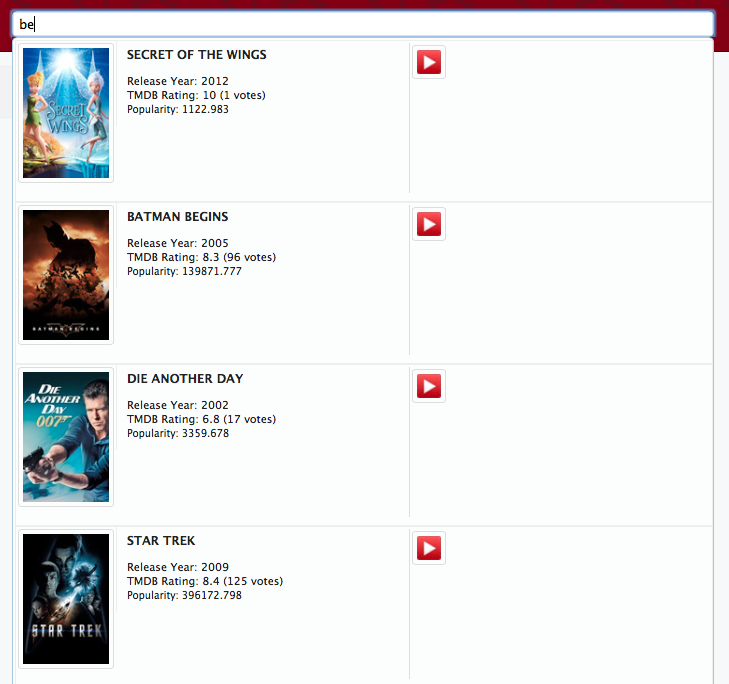
But if you prepend the search term with the "@" sign, for example "@be" it starts to find persons (actors/directors) and sharemovi.es users in the same search:
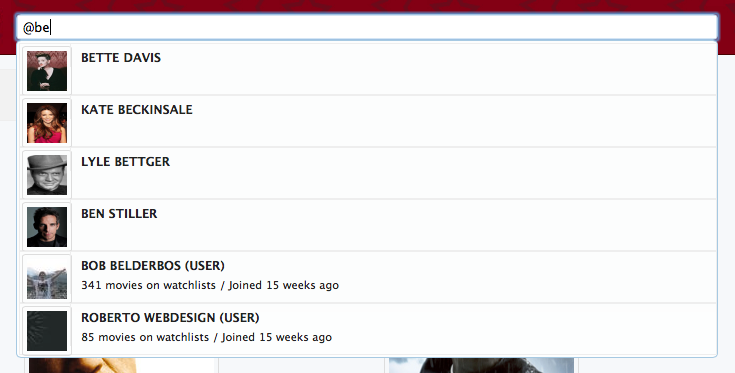
Implementation
This is an extension to the movie search interface with instant trailers I blogged about last year.
Autocomplete plugins work with AJAX: javascript calls a serverside script (PHP in this case) which returns its result in a certain format (JSON in this instance). Javascript digests this result and sticks it into the DOM.
The backend script (search.php) looks like:
<?php
if (!isset($_GET["term"])) {
return;
}
include 'libs/functions.php';
$term = $_GET["term"];
$orgTerm = $term;
$lang = 'en'; # for now
$return_arr = array();
# limit size of autocomplete window
$maxNumItems = array();
$maxNumItems['movies'] = 5; # 5 items for movies because the content is big
$maxNumItems['persons'] = 4; # persons can add up to 7, 4 for api, 3 for users
$maxNumItems['users'] = 3;
$counter['movies'] = 0;
$counter['persons'] = 0;
$counter['users'] = 0;
# formatting in JS: http://stackoverflow.com/questions/6070142/jquery-ui-formatting-the-autocomplete-results-add-image-possible
# searches starting with @ search for persons (actors / directors from the API) or sharemovies users
if(preg_match('/^@/i', $term)){
$term = preg_replace('/^@s*/i','',$term);
$term = urlencode($term);
# 1. persons
$results = queryApi3('','','search/person', $term, '', $lang);
if(! empty($results->results)) {
foreach($results->results as $person) {
if ($person->adult == true || $person->profile_path == '') continue;
$counter['persons']++;
$row_array['type'] = "person";
$row_array['id'] = $person->id;
$row_array['value'] = $person->name;
$row_array['img'] = $POSTER_SMALL . $person->profile_path;
$row_array['slug'] = createSlug('person',$person->id,$person->name);
array_push($return_arr,$row_array);
if($counter['persons'] == $maxNumItems['persons']) {
break;
}
}
}
# 2. users in db
include "libs/db_connect.php";
$term = $mysqli->real_escape_string($term);
$search_term = str_replace(array("+"), " ", $term);
$q = "SELECT shmov_users_movies.id,shmov_users.name,shmov_users.ins as joined,count(shmov_users_movies.id) as total ";
$q .= "FROM `shmov_users_movies` join shmov_users on shmov_users_movies.id=shmov_users.id ";
$q .= "WHERE LCASE(shmov_users.name) like '%$search_term%' ";
$q .= "group by shmov_users_movies.id order by total desc";
$r = $mysqli->query($q);
if($r->num_rows) {
while($row = $r->fetch_object()){
$counter['users']++;
$row_array['type'] = "user";
$row_array['id'] = $row->id;
$row_array['value'] = $row->name . " (user)";
$row_array['total'] = "<small>" . $row->total . " movie" ;
$row_array['total'] .= ($row->total != 1)? "s": "" ;
$row_array['total'] .= " on watchlists";
$row_array['joined'] = " / Joined " . timeAgo($row->joined) . "</small>";
$row_array['img'] = "https://graph.facebook.com/".$row->id."/picture?width=40&height=40";
$row_array['slug'] = "user/".$row->id;
array_push($return_arr,$row_array);
if($counter['users'] == $maxNumItems['users']) {
break;
}
}
}
# if nobody found return error message (see JS: it expects a message to start with Oops)
if(empty($return_arr)){
array_push($return_arr, "Oops ... nobody found for $orgTerm");
}
} else {
# else = movie title search
$term = urlencode($term);
$results = queryApi3('','','search/movie', $term, '', $lang);
if(empty($results->results)) {
# if nobody found return error message (see JS: it expects a message to start with Oops)
array_push($return_arr, "Oops ... no movies found for $orgTerm");
} else {
foreach($results->results as $movie) {
$counter['movies']++;
$row_array['type'] = "movie";
$row_array['id'] = $movie->id;
$row_array['value'] = ucwords($movie->title);
if($movie->original_title && ($movie->title != $movie->original_title)) {
$row_array['org'] = ucwords($movie->original_title);
} else {
$row_array['org'] = '';
}
$row_array['pop'] = $movie->popularity;
$row_array['rating'] = $movie->vote_average . " (". $movie->vote_count." votes)";
$row_array['plot'] = get_n_words($movie->overview, 15) . " ..." ;
$row_array['year'] = substr($movie->release_date, 0, 4);
$row_array['img'] = $POSTER_SMALL . $movie->poster_path;
$row_array['slug'] = createSlug('movie',$movie->id,$movie->title);
array_push($return_arr,$row_array);
if($counter['movies'] == $maxNumItems['movies']) {
break;
}
}
}
}
echo json_encode($return_arr);
?>
- The search term is sent from JS, if it starts with @ it performs a search against themoviedb and against the users in the sharemovies database. If no @ is prepended to the search, it does a regular movie search, again against themoviedb API. I could cache the results but for now the search box use seems within the themoviedb limits (I do cache movie and person pages though which reduces the amount of calls to the API significantly).
- The $maxNumItems array restricts the number of items in the returned result so that the autocomplete result box fits reasonably well within the page.
- The json_encode is run on the array of row arrays for JS consumption.
- queryApi3 is a routine to query themoviedb API, I omitted it for brevity, interesting in more details, just drop me a line ...
The Javascript code to digest the result (after including the jQuery library):
$(document).ready(function() {
..
..
// prevent autocomplete field from being submitted on enter
// actually ace's solution worked here: http://stackoverflow.com/questions/7237407/stop-enter-key-submitting-form-when-using-jquery-ui-autocomplete-widget
$("input#autocomplete").keypress(function(event){
var keycode = (event.keyCode ? event.keyCode : event.which);
if (keycode == '13') {
event.preventDefault();
event.stopPropagation();
}
});
$("input#autocomplete").autocomplete({
search: function(event, ui) {
$('.spinner').show();
},
open: function(event, ui) {
$('.spinner').hide();
},
source: "search.php",
minLength: 2,
select: function(event, ui) {
$('.spinner').show();
var currentUrl = document.URL;
var baseUrl;
if( currentUrl.match(/sharemovi.es/) ){
baseUrl = "http://sharemovi.es/";
} else {
baseUrl = "http://127.0.0.1/sharemovies/";
}
var redirectTo = baseUrl + ui.item.slug;
location.href=redirectTo;
}
}).data( "autocomplete" )._renderItem = function( ul, item ) {
if(item.value.match(/^Oops/)) {
return $( "<h2 class='notfound'></h2>" )
.data( "item.autocomplete", item )
.append( "<p>"+item.value+"</p>" )
.appendTo( ul );
} else {
var movieInfo = '';
movieInfo += "<a id="+item.id+">";
movieInfo += "<img src='" + item.img + "' />";
movieInfo += "<span><h4>" + item.value+ "</h4>";
if(item.type == "user"){
movieInfo += item.total;
movieInfo += item.joined;
}
if(item.type == "movie"){
movieInfo += "<small><p>";
if(item.org) movieInfo += "Original Title: "+item.org+"<br>";
movieInfo += "Release Year: "+item.year;
movieInfo += "<br>TMDB Rating: "+item.rating;
movieInfo += "<br><small>Popularity: "+item.pop;
movieInfo += "</small></p>";
movieInfo += "<div id='"+item.value+' '+item.year;
movieInfo += "' class='trailer'>";
movieInfo += "<img src='i/youtube.png'>";
movieInfo += "</div></small>";
}
movieInfo += "</span></a>";
$( "<li></li>" )
.data( "item.autocomplete", item )
.append( movieInfo )
.appendTo( ul );
// if search is for person or user, the autocomplete box needs to be smaller
if(item.type == "user" || item.type == "person") {
$(".ui-autocomplete li").css("height", "50px");
$(".ui-autocomplete li a").css("height", "50px");
$(".ui-autocomplete li a img").css({"height": "40px", "width": "40px"});
$(".ui-autocomplete li a span").css("left", "50px");
}
return false;
}
};
..
..
// more sharemovies JS code ..
..
..
});
- source: "search.php" => here you see the backend PHP script being called.
- .data( "autocomplete" )._renderItem => this consumes the elements returned by the PHP backend script. It wraps it in convenient HTML I styled with CSS (which exact styling is beyond the scope of this tutorial).
- Note in the last part I overwrote some of the CSS rules of the autocomplete jQuery plugin to present smaller entries for person vs. movie results (see printscreens at the start of this post). The movie results give back more verbose data. So now each result takes up just the necessary space.
- Some things are hardcoded like the sharemovi.es domain name and the handling of no results ("item.value.match(/^Oops/)") but that is fine for now.
At last the form html that has the DOM element Javascript acts upon:
<form action="#" id= "searchForm" method="post">
<p class="ui-widget">
<input type="text" id="autocomplete" name="autocomplete" class="defaultText"
title="Search movie ... [ use '@' for actors/directors/sharemovies users ] "/>
</p>
</form>
This tutorial gives you a 90% jumpstart how to implement a rich multi-functional autocomplete. I hope it inspires you to build something similar. Also let me know if you have implemented a similar feature in any other language.