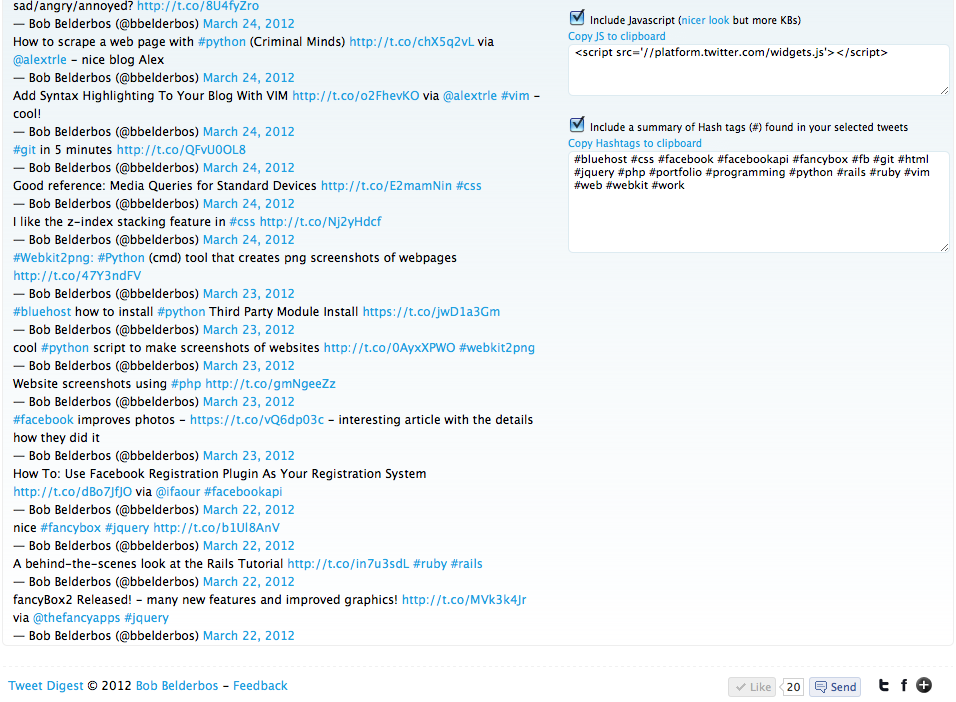
My Reading List improved - a quick tour of its new features
I have further tweaked the My Reading List Facebook app. In this post a quick tour with printscreens of its new features.

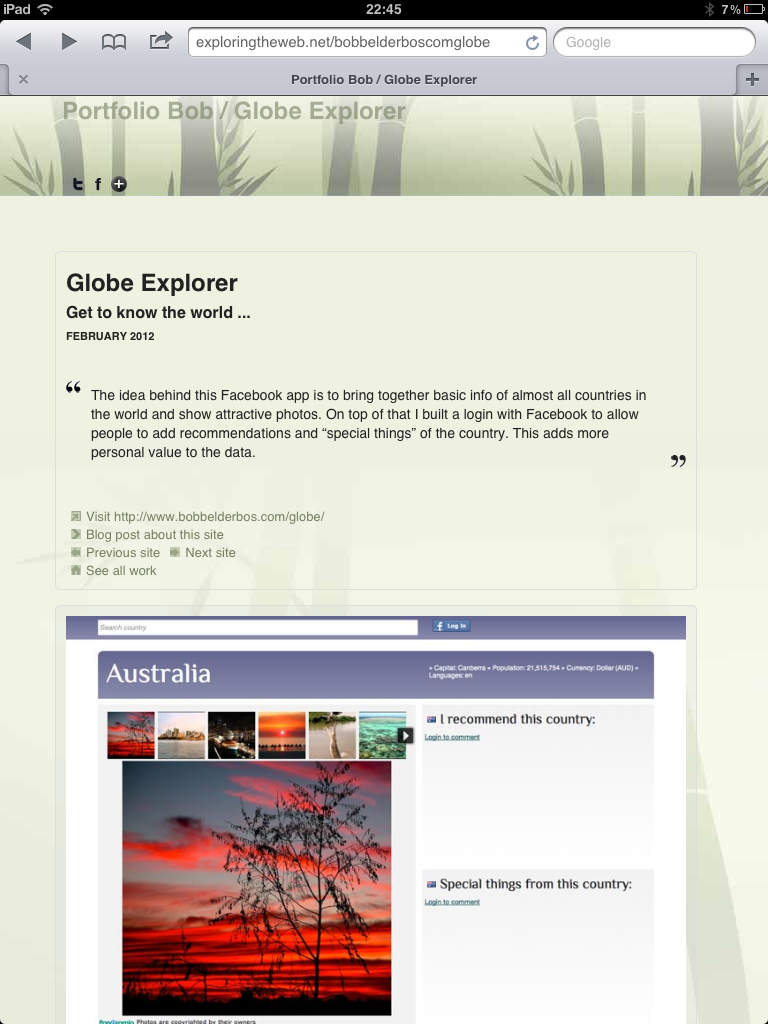
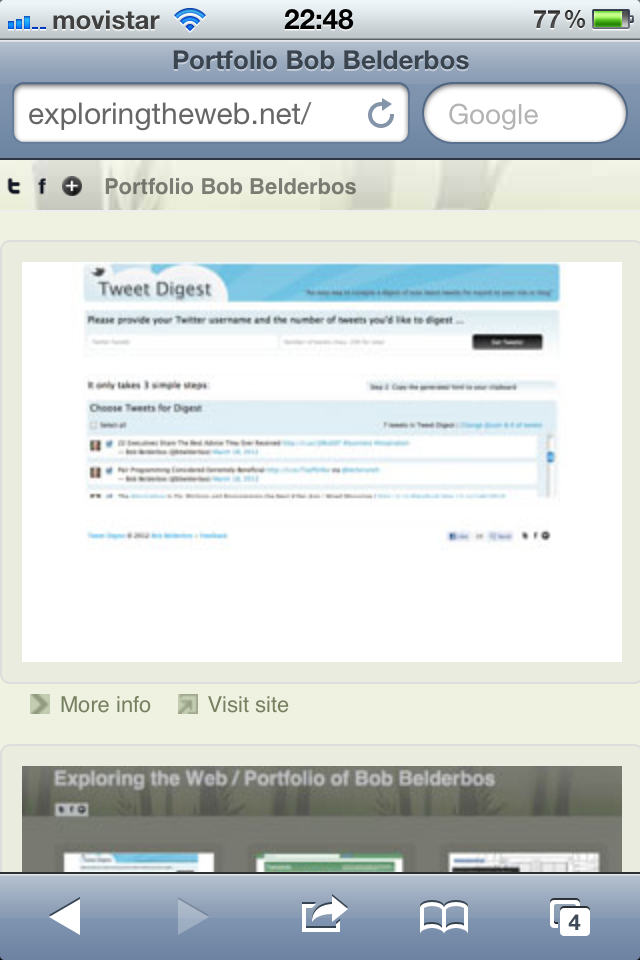
This has been promoted to one of my favorite web/programming projects now :) The Google Books API does a great job in providing rich content for a wide range of books. With the integration of the Amazon customer reviews and the info My Reading List users are adding, it is becoming a powerful tool to share your reading and inform yourself about potential next reads and/or book purchases. With this new release, it is easier to find and add new books to your list. You can find much more info per book. And the overall look and feel have been improved as well. A quick tour what is new:
3-way autocomplete
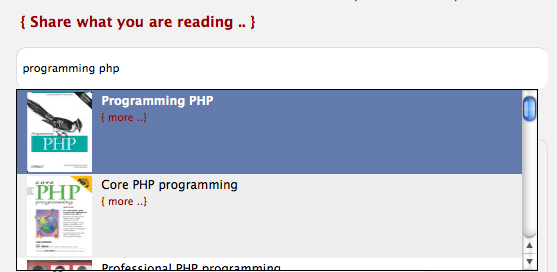
When you search a book from the search box in the header you get a result devided in: 1. books already added and by who, 2. books not added but found by the Google Books API with a link to add them, 3. matching usernames for the search string sorted descending on the number of books added:
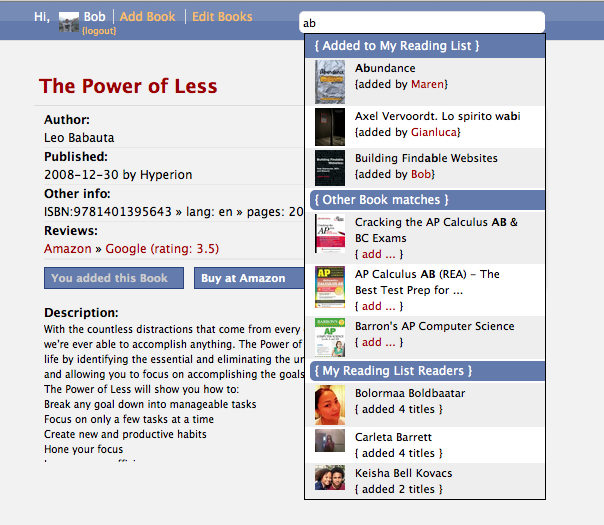
The "adding book" autocomplete search box
... is always visible now. It was hidden behind an "add book" button. This was not necessary so I made it always visible at the top of the homepage:
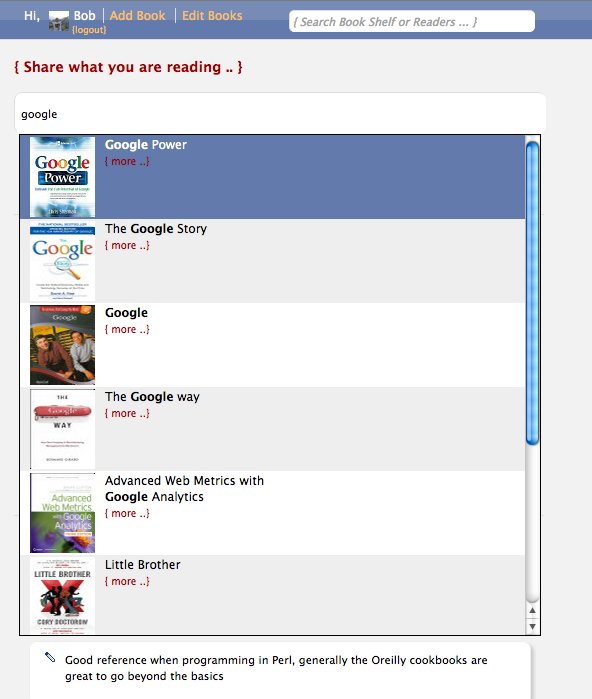
When you select a book from the autocomplete a form slides down to add it to your reading list:
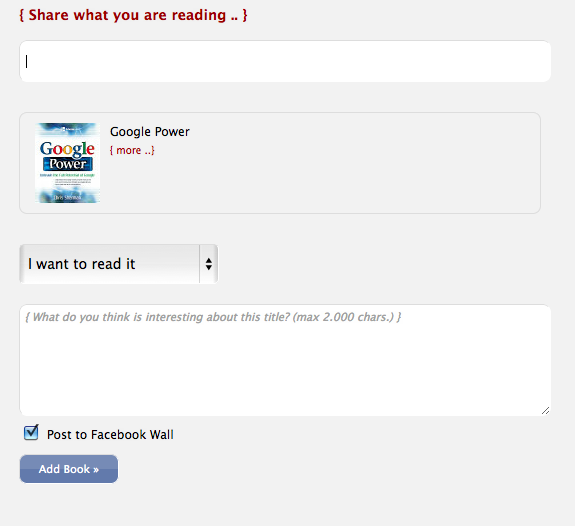
Edit everywhere
Instead of one edit place, the app shows you click-to-edit buttons (nice jQuery plugin) everywhere it detects a book from you:
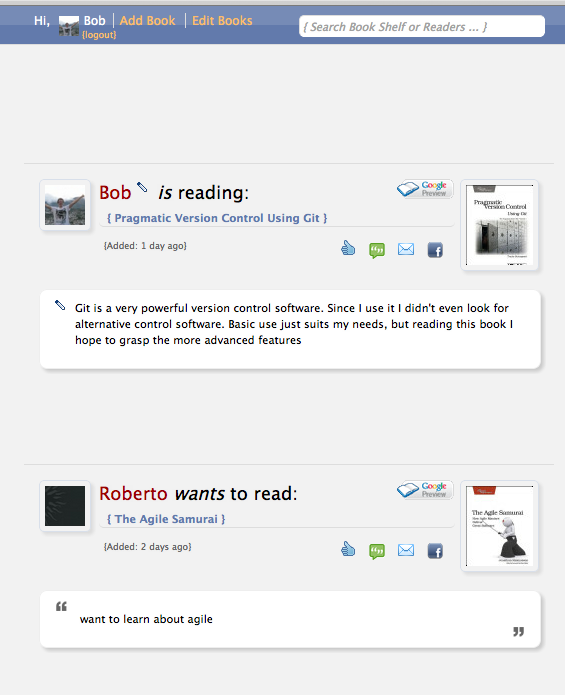
Easier to find your books
After some time you can build up quite a reading list. When you click on "Edit Books", you get an overlay with your books. At the top you find a filter box that, when you start typing, show you matching titles on the fly:
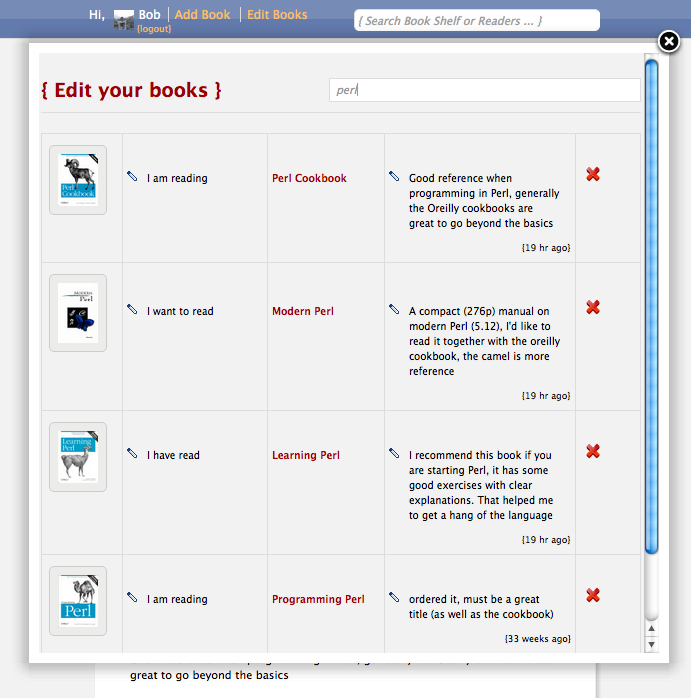
New book pages
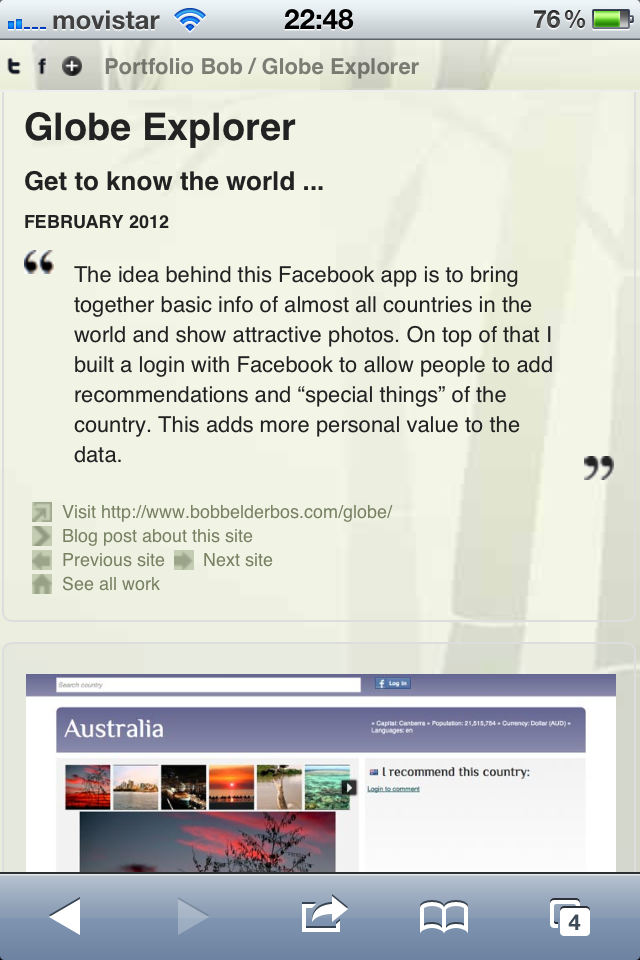
Each book has a page with more info than before, apart from the Amazon reviews, this data comes from the Google Books API:
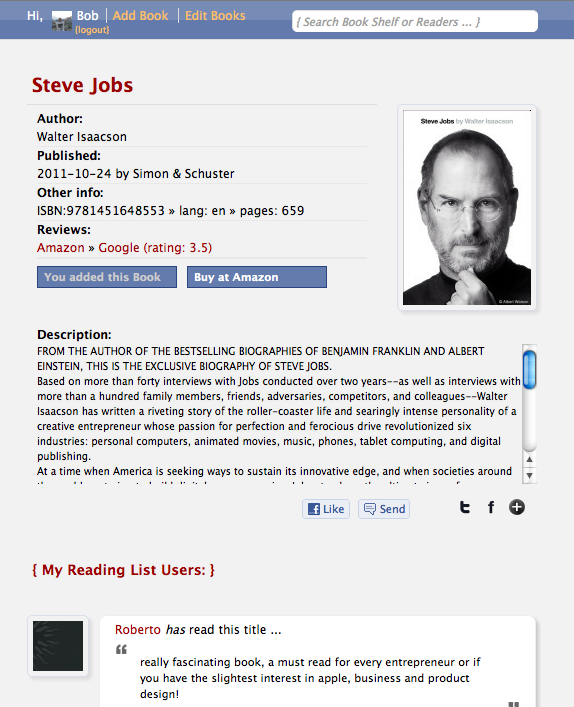
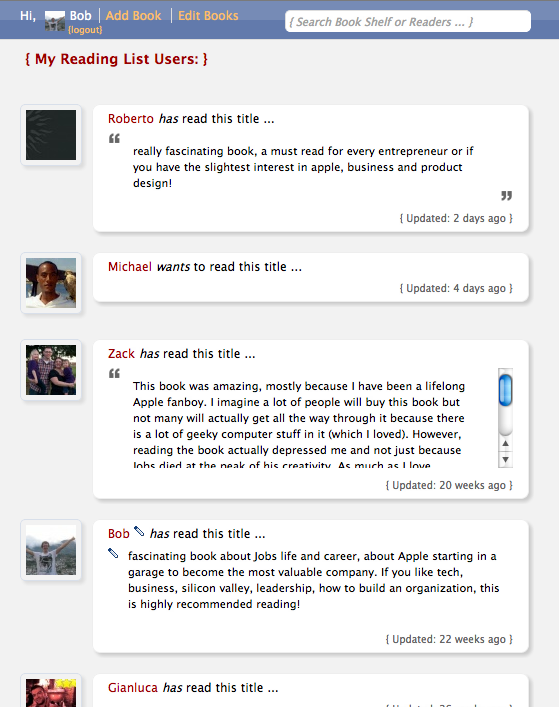
And as more people start adding books, sometimes you see multiple reviews from My Reading List users for the same book (Steve Jobs bio as an example here)
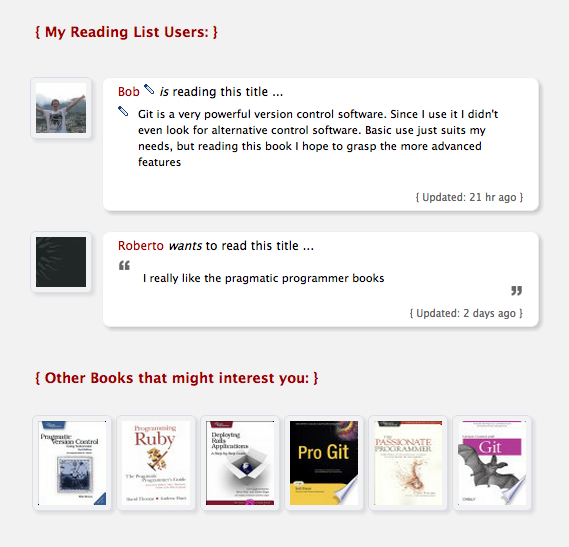
Similar books
Google Books API can be queried for similar titles, that is what I integrated further down the book pages (example for a book about Git version control software):
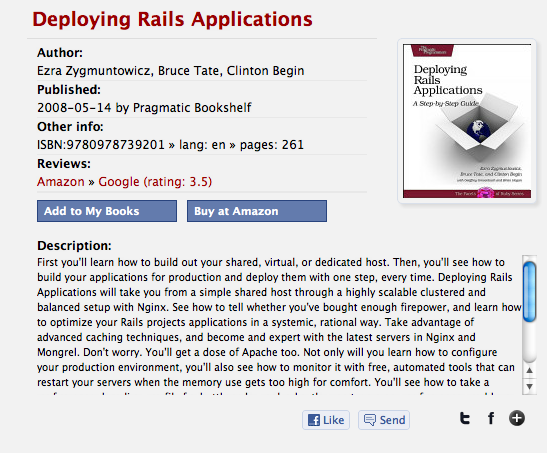
Easily add books to your reading list
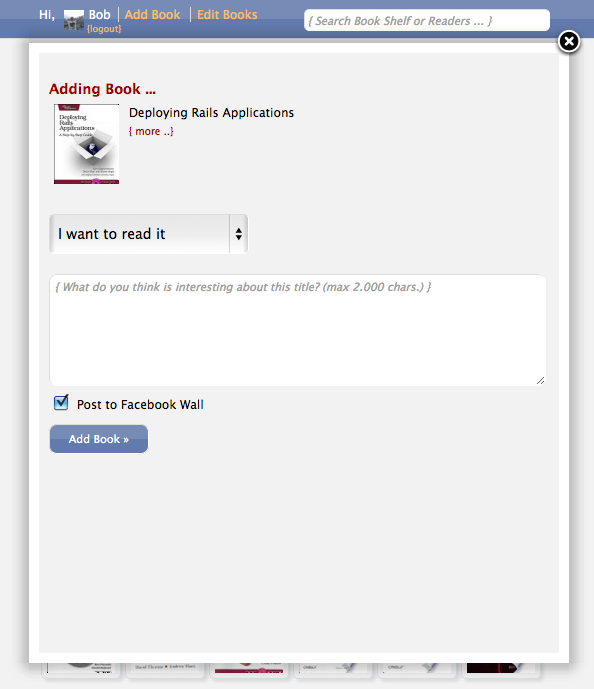
... from the book page, if you click the "Add to My Books" button, you get an overlay identical to the "add book" form we saw before. When you add it with or without review, the overlay closes, the page refreshes and you are linked to that book.
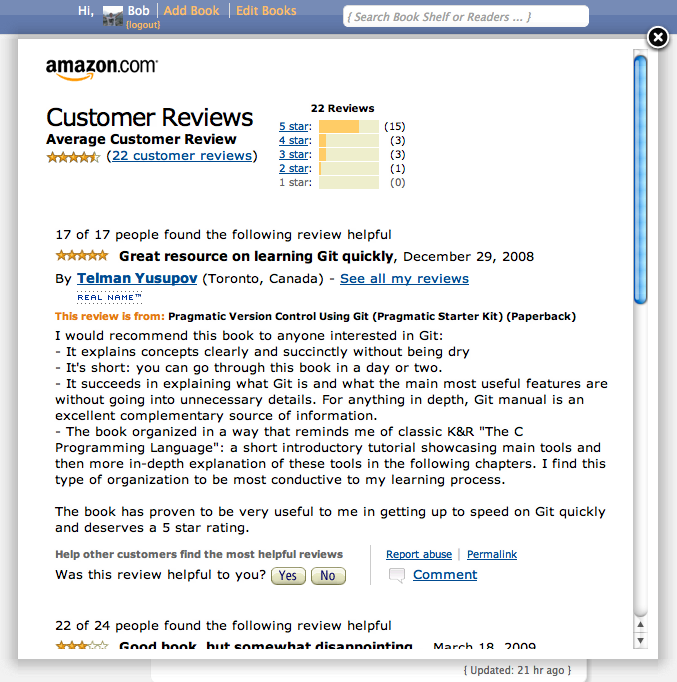
Amazon reviews
Last but not least, and one of my favorites: integration of Amazon customer reviews. I really wanted this feature to be integrated! Today I had some time to check out the Amazon Product Advertising API. It had some nice technical challenges which I will dedicate another blog post to. If the app manages to get an iframe URL with reviews it is visible on the books page. There is also a link to the Google Books reviews (different sources is a good thing!) and a link to buy the book at Amazon:
Where is it?
As mentioned in my last post I put My Reading List on its own domain now. You can subscribe to updates by following the My Reading List Facebook page. All new titles that get added are streamed to Twitter as well.
Previous blog posts
If you have doubts or questions, or you just want to know more about this app and its feautes, I have been blogging about it for a while now (descending order):
- 2012/05 > Release notes My Reading List v1.1
- 2011/09 > My Reading List Widget
- 2011/09 > My Reading List: load Google book preview in overlay
- 2011/09 > Nice Jquery plugin: Jeditable
- 2011/03 > Hi folks, what are you reading? Share it on “My Reading List”